User:Darwin2049/ChatGPT4 Operations
Overview
Theory of Operations
CG4 – Terms, Theory of Operation: CG4 is a narrow artificial intelligence system that is a Generative Pre-trained Transformer.
In order to make sense of this one would be well advised to understand several fundamental concepts associated with this technology. Because this is a highly technical subject the following is intended to introduce the core elements. The reader is encouraged to review the literature and body of insight that is currently available as explanatory video content.
By way of clarifying the topics of this work we organize these concepts into two primary groups. The first group offer basic information
on the fundamental building blocks of Large Language Models of which CG4 is a recent example. The second group introduces or otherwise clarifies
terms that have come to the forefront of recent public discussions and issues.
Fundamental Building Block Concepts.
- GPT3: a smaller precursor version of the GPT4 system;
- GPT3.5: a higher performance version of GPT3 but still falls short of the full-up GTP4 successor;
- GPT4: a LLM with over one trillion parameters;
- Chat GPT4: the conversational version of GPT4;
- Artificial Neural Networks. Four excellent episodes providing very useful insight into some underlying theory of how artificial neural networks perform their actions.
- From 3Blue1Brown: Home Page
- Neural_Network_Basics Some basic principles in how neural networks structures are mapped to a problem.
- Gradient Descent A somewhat technical topic requiring a careful examination on the part of the reader who is unfamiliar with the mathematical background.
- Back Propagation, intuitively, what is going on?
It graphically shows the mathematics behind how a neural network attempts to "home in" on a target; what we can see is the mathematics that underlies how training is iteratively done and the distance difference between the neural network's learning state gradually begins to converge with the actual desired response; - Back Propagation Theory How various layers in a deep learning neural network interact with each other.
A much closer mathematical description of how prior and successive neuron values contribute to successive neuron values; then how they ultimately contribute to the output neuron that they connect to and whether it will activate or not; this is a highly mathematical description using advanced partial derivative calculus;
- From 3Blue1Brown: Home Page
- Deep Learning: the technique of using representing an artificial neural network type structure to solve extremely complex problems; a neural network it typically will work using a large number of what are called "hidden layers"; they achieve greater performance when they are trained on very large data sets; these data sets can range from millions to billions of examples;

- Hidden Layer: One or more network layers that stands between an input layer and the final output layer. Each input layer is connected to all of the nodes in the first hidden layer. Subsequent hidden layers are added as a means to provide greater discriminatory resolution to the neural network. Each node in a hidden layer can be connected to each node in the following hidden layer. The more hidden layers the more sophisticated can be the ability of the neural network to perform its tasks.
In neural networks, a hidden layer is located between the input and output of the algorithm, in which the function applies weights to the inputs and directs them through an activation function as the output. In short, the hidden layers perform nonlinear transformations of the inputs entered into the network. Hidden layers vary depending on the function of the neural network, and similarly, the layers may vary depending on their associated weights. Useful insight into what hidden layers are doing can be viewed using this hidden layers video
For an interactive view of how hidden layers enable a neural network to learn a new function one can monitor
this video by sentdex; it has no audio but provides excellent insight into how the various layers and nodes within a layer develops an approximation of the function that it is attempting to learn.

- Parameters: are the coefficients of the model and they are chosen by the model itself. It means that the algorithm, while learning, optimizes these coefficients (according to a given optimization strategy) and returns an array of parameters which minimize the error. To give an example, in a linear regression task, you have your model that will look like y=b + ax, where b and a will be your parameter. The only thing you have to do with those parameters is to initialize them.
- Tokens: Making text into tokens. These become vector representations. They form the basis of the neuron values for each neuron in a neural network. The narrator provides a short and succinct introduction to the basic concepts of what a token is and how it is represented as a vector.
Types
- Generative Artificial IntelligenceGenerative artificial intelligence (AI) is artificial intelligence capable of generating text, images, or other media, using generative models. Generative AI models learn the patterns and structure of their input training data and then generate new data that has similar characteristics. A detailed oil painting of figures in a futuristic opera scene Théâtre d'Opéra Spatial, an image generated by Midjourney. In the early 2020s, advances in transformer-based deep neural networks enabled a number of generative AI systems notable for accepting natural language prompts as input. These include large language model chatbots such as ChatGPT, Bing Chat, Bard, and LLaMA, and text-to-image artificial intelligence art systems such as Stable Diffusion, Midjourney, and DALL-E.

A summary of the key elements of what generative artificial intelligence are explained in this video (11 minutes); note that a key and crucial point to keep in mind is that generative ai generates new output based upon a user's request or query; it uses massive amounts of training data to draw from in order to generate its output; note further that the "G" in GPT is derived from generative artificial intelligence;
Subsequent developments with generative ai systems have been moving forward apace at companies such as IBM. Their efforts are targeting a range of salient topic areas. To name a few their teams are addressing topics such as molecular structure, code, vision, earth science.
- Encoder-Decoder. According to Analytics Yogi In the field of AI / machine learning, the encoder-decoder architecture is a widely-used framework for developing neural networks that can perform natural language processing (NLP) tasks such as language translation, etc which requires sequence to sequence modeling. This architecture involves a two-stage process where the input data is first encoded into a fixed-length numerical representation, which is then decoded to produce an output that matches the desired format. As a data scientist, understanding the encoder-decoder architecture and its underlying neural network principles is crucial for building sophisticated models that can handle complex data sets. By leveraging encoder-decoder neural network architecture, data scientists can design neural networks that can learn from large amounts of data, accurately classify and generate outputs, and perform tasks that require high-level reasoning and decision-making. An excellent if somewhat technical video describes and explains the architecture of what is going on with the encoder and decoder components of the GPT system.
- Bidirectional Encoder Representations from Transformers (BERT) An insightful paper on several key features of what BERT is about and how it functions. official archive paper on BERT.
- BERT - very useful video a prediction system that uses training data that uses statistical mechanisms to anticipate a subsequent input based upon the most recent input;
- Large Language Model. Is a prediction system that uses training data to enable a deep neural network to perform recognition tasks. It uses statistical mechanisms to anticipate subsequent input based upon the prior input. Prediction systems use this training data to iteratively condition and train the deep learning system for its specific tasks. The following two videos provide focus on large language models; this is part one of large language models. it describes how words are used to predict subsequent words in an input text; here is part two and it is an expansion upon the earlier video but offers more technical detail. Together they provide a fairly concise synopsis of how large language models make predictions of how words are associated with each other in a body of text. They explain further how they require a very large training data set so as to achieve their performance.

- Transformer. (conceptually) This discussion presents key concepts of how transformers work from a more conceptual point of view. Its architecture relies on what is called parallel multi-head attention mechanism. The modern transformer was proposed in the 2017 paper titled "Attention is all you need".
There is some overlap with topics described above in the section on encoder-decoder architecture. A significant contribution is because it enables creation of a neural network model that requires less training time than previous recurrent neural architectures; It addressed such issues as inadequate long short-term memory (LSTM); this had been a shortcoming for earlier models because contextually significant terms might be beyond the positional proximity of semantically meaningful terms. Its later variation have been adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl, by virtue of the parallelized processing of input sequence. Earlier efforts to resolve such difficulties were fundamentally influenced by the paper by Ashish Vaswani et al of the Google Brain team. A breakdown of its major concepts are presented in:- Attention is all you need. - Generative Pre-trained Transformer: Generative pre-trained transformers (GPT) are a type of large language model (LLM) and a prominent framework for generative artificial intelligence. The first GPT was introduced in 2018 by OpenAI. GPT models are artificial neural networks that are based on the transformer architecture, pre-trained on large data sets of unlabeled text, and able to generate novel human-like content. As of 2023, most LLMs have these characteristics and are sometimes referred to broadly as GPTs. An overview of the important features can be viewed in the narrator touches on a number of related topics as well.
- Generative Adversarial Networks. a GAN is A generative adversarial network (GAN) is a class of machine learning framework and a prominent framework for approaching generative AI. The concept was initially developed by Ian Goodfellow and his colleagues in June 2014. In a GAN, two neural networks contest with each other in the form of a zero-sum game, where one agent's gain is another agent's loss.
Given a training set, this technique learns to generate new data with the same statistics as the training set. For example, a GAN trained on photographs can generate new photographs that look at least superficially authentic to human observers, having many realistic characteristics. Though originally proposed as a form of generative model for unsupervised learning, GANs have also proved useful for semi-supervised learning, fully supervised learning, and reinforcement learning. This video provides a short synopsis of the GANS capability. - Recurrent Networks. A recurrent neural network is a kind of deep neural network created by applying the same set of weights recursively over a structured input, to produce a structured prediction over variable-size input structures, or a scalar prediction on it, by traversing a given structure in topological order. Fully recurrent neural networks (FRNN) connect the outputs of all neurons to the inputs of all neurons. This is the most general neural network topology because all other topologies can be represented by setting some connection weights to zero to simulate the lack of connections between those neurons. The illustration to the right may be misleading to many because practical neural network topologies are frequently organized in "layers" and the drawing gives that appearance. However, what appears to be layers are, in fact, different steps in time of the same fully recurrent neural network. A recurrent neural network is a kind of deep neural network] created by applying the same set of weights recursively over a structured input, to produce a structured prediction over variable-size input structures, or a scalar prediction on it, by traversing a given structure in topological order. For an intuitive overview of recurrent neural networks have a look here
- Recursive Networks. A recursive neural network is a kind of deep neural network created by applying the same set of weights recursively over a structured input, to produce a structured prediction over variable-size input structures, or a scalar prediction on it, by traversing a given structure in topological order. Recursive neural networks, sometimes abbreviated as RvNNs, have been successful, for instance, in learning sequence and tree structures in natural language processing, mainly phrase and sentence continuous representations based on word embedding. RvNNs have first been introduced to learn distributed representations of structure, such as logical terms. Models and general frameworks have been developed in further works since the 1990s. Addressing the task of attempting to transition from words to phrases in natural language understanding was addressed using recursive neural networks. A short but useful video presents several core elements of how the problem was solved.
- Fine Tuning CG4. Use instructions from the OpenAI Documentation page to fine tune CG4. Here is some insight on how to fine tune a Chat GPT3.5 system. For a somewhat less technical overview on when to use fine tuning and some basic instructions on how to perform fine tuning then have a look at this video. For observers with an interest in more practical uses then this video explains how to perform fine tuning to capture business knowledge.
- Supervised or Unsupervised Learning. Supervised learning (SL) is a paradigm in machine learning where input objects (for example, a vector of predictor variables) and a desired output value (also known as human-labeled supervisory signal) train a model. The training data is processed, building a function that maps new data on expected output values. An optimal scenario will allow for the algorithm to correctly determine output values for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way (see inductive bias). This statistical quality of an algorithm is measured through the so-called generalization error. This short video presents a summarized explanation of the difference. Unsupervised learning is a paradigm in machine learning where, in contrast to supervised learning and semi-supervised learning, algorithms learn patterns exclusively from unlabeled data.
- Pretrained. A pretrained AI model is a deep learning model — an expression of a brain-like neural algorithm that finds patterns or makes predictions based on data — that’s trained on large datasets to accomplish a specific task. It can be used as is or further fine-tuned to fit an application’s specific needs. Why Are Pretrained AI Models Used? Instead of building an AI model from scratch, developers can use pretrained models and customize them to meet their requirements. To build an AI application, developers first need an AI model that can accomplish a particular task, whether that’s identifying a mythical horse, detecting a safety hazard for an autonomous vehicle or diagnosing a cancer based on medical imaging. That model needs a lot of representative data to learn from. This learning process entails going through several layers of incoming data and emphasizing goals-relevant characteristics at each layer. To create a model that can recognize a unicorn, for example, one might first feed it images of unicorns, horses, cats, tigers and other animals. This is the incoming data.
Then, layers of representative data traits are constructed, beginning with the simple — like lines and colors — and advancing to complex structural features. These characteristics are assigned varying degrees of relevance by calculating probabilities. As opposed to a cat or tiger, for example, the more like a horse a creature appears, the greater the likelihood that it is a unicorn. Such probabilistic values are stored at each neural network layer in the AI model, and as layers are added, its understanding of the representation improves. To create such a model from scratch, developers require enormous datasets, often with billions of rows of data. These can be pricey and challenging to obtain, but compromising on data can lead to poor performance of the model.

- Autonomous Agent: an instance of CG4 that is capable of formulating goals and then structuring subtasks that enable the achievement of those subtasks. A recent development has come to light wherein researchers at Stanford University and Google were able to demonstrate autonomous and asynchronous problem solving by having CG4 able to call instances of itself or of CG3. The result was that they were able to create collective of asynchronous problem solvers. They enabled these problem solvers a mechanism to interact and communicate with each other. The result was a very small scale simulation of a village. The "village" consisted of 25 agents. Each agent was assigned private memory as well as goals.
Of note is that the agent architecture is a bare bones minimal set of behavior controllers. A much more complex and sophisticated set can be envisioned wherein each agent can be developed out to the point that they become far more lifelike. This can mean that they might have goals but such characteristics as beliefs, which allow for correct or incorrect understanding, theory of mind of other agents, or users.
It would be a fairly small step to postulate a substantially larger collection of agents. This larger collection of agents might be put to the use of solving problems involving actual real people in real world situations. For instance one can imagine creating a population consisting of hundred or thousands of agents. These agents might be instantiated to possess positions or values regarding a range of topics. They can further be configured to associate themselves with elements or factors in the world that they operate in.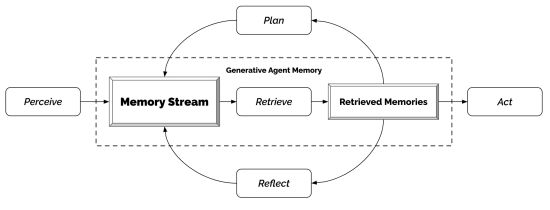
For instance, a subset of agents might be instantiated to exhibit a value to specific factors in the sim-world. A more concrete example might be that they attach considerable value to having the equivalent of "traffic management", i.e. the analog of "traffic lights" in their world vs. having the equivalent of "stop signs"; other agents might possess nearly opposite value; this sets up the possibility that in a larger collective that conflict can arise. With that conflict there might develop agents that lean toward mediation and compromise. Others might be more adamant and less cooperative. The upshot is that very complex models of human behavior can be modeled by adding more traits beyond those of goals and memory.

Recently there appears to have been a shift in landscape of the topic of artificial intelligence agents. What now appears to be coming into focus is the ability to construct specifically targeted tools that make use of multiple autonomous agents to cooperatively solve problems. Knowledgeable observers have been taking note of this trend and providing insight into what it means and how it might affect the further development of the field.